Fellow Spark developers, hearken to me! How fast is your Spark development cycle? Slow? Really slow? You could use this super awesome template to enable running your Spark jobs in IntelliJ, but sometimes you’re constrained by the size/locality of the data you’re working with, and you find that each re-run takes time (which is precious and finite and all that so yes, this stuff matters).
The craftier of you might turn to that most estimable of tools, the REPL (Read-Evaluate-Process-Loop) for quick command-line iteration. And that’s a good start. I use the Scala REPL on a daily basis, mostly to verify proper date/time formats and regex testing. Using the REPL with Spark, you don’t have the overhead of starting up/shutting down the SparkContext and you can quickly test out things with immediate feedback (cool). And you can enter the REPL from SBT using the console command, giving you access to the classes/utilities you’ve built in that project and the project dependencies (very cool).
A Better Way
So yes, the REPL is nice and all but you can go even FURTHER, FASTER with notebooks like Apache Zeppelin. Zeppelin (like Jupyter) allows you to write snippets of runnable code in notebooks and execute them from the browser. What separates Zeppelin from Jupyter is how well it works out of the box with Spark. Spark is the default interpreter for Zeppelin and provides the spark and sql contexts for you implicitly. You also get great visualizations of SQL queries for free.
 |
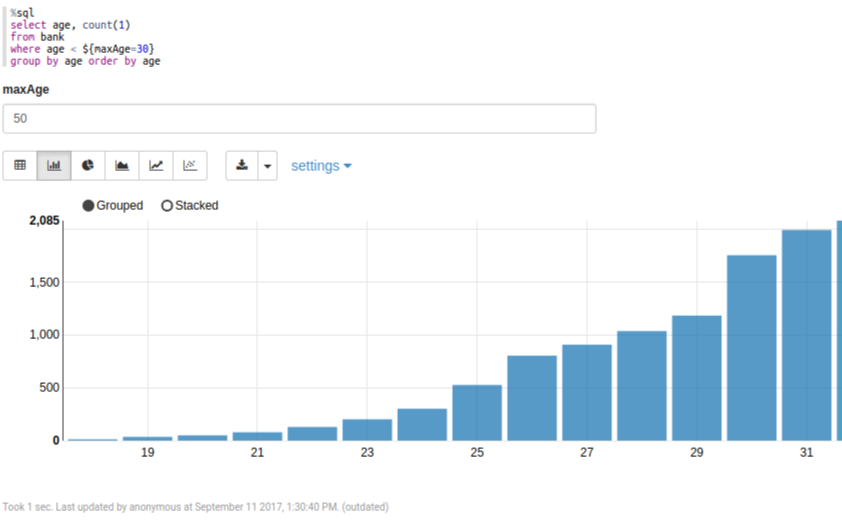 |
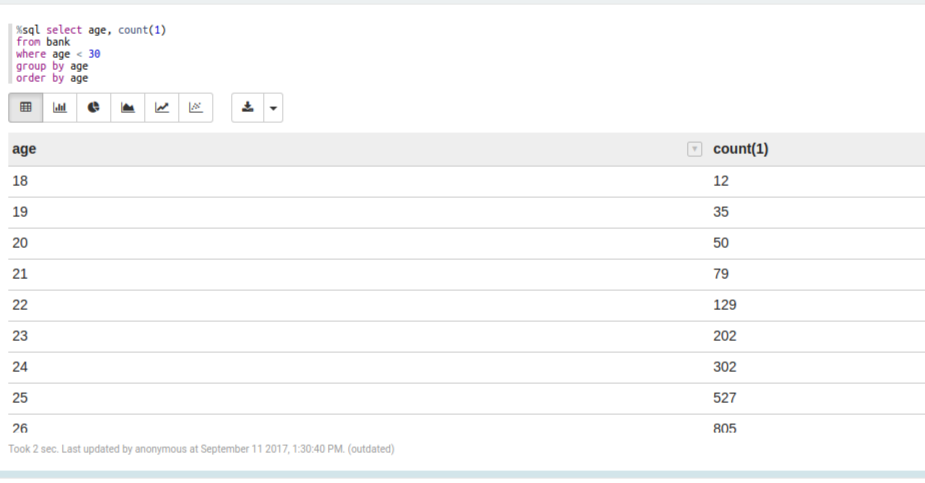
With Zeppelin, if you’re trying to query some dataset and want to understand its total size, the cardinality of a column, or simple descriptive statistics, you can do that immediately from the notebook itself with simple SQL queries. This sounds trivial but it ABSOLUTELY saves you time and effort by giving you a tight feedback loop when asking questions of data and not having to reload it every single time (when you use cache). In addition, you get documentation for free with Markdown, data visualization support with Angular, a growing ecosystem of modules in the Big Data ecosystem, and simple support for collaboration and sharing among your team.
I also think Zeppelin helps you write more scalable Spark code. Writing code in paragraphs reinforces the idea of making methods as small and concise as possible. Once these chunks of code are worked out, building out your codebase is more or less a matter of composing these chunks into logical classes or methods.
Zeppelin does have it’s drawbacks. Switching between your actual code and the notebook can be challenging, so you need dedicated contexts of exploration (Zeppelin) vs. crafting a solution (codebase) and stick to them. Also, dependency management is too manual. I would love for Zeppelin to know everything my Spark job knows through some Vulcan mindmeld or something (did I use that term correctly? I’m not a Trekkie. I’m a whatever-you-call-Tolkien-book-lover-two-generations-removed. Ringer? Inkling? Istari?).
Big Idea Section
Ultimately, I think Zeppelin is a great tool if you’re a Spark developer trying to build scalable systems in a reasonable amount of time. I think notebooks are “what’s next”. I think speed of development can be a big bottleneck to the software engineering process, especially when working with large volumes of data. I also think, most importantly, that any company of reasonable size needs a certain level of useful, live documentation to understand just what the hell they’re doing.
Because knowledge is power right? Isn’t all of this “coding”, “documentation”, and “testing” just different ways to represent knowledge? Ultimately knowledge is just a tool, a means to achieve some goal. It’s incumbent on us as engineers to use the best tools we can to accomplish our goals. I think Zeppelin is one such tool. I also think we could take this idea further and eventually get to the point where all of the code we write is just simple chunks, easily composable with minimal overhead (why do we spend so much time on packaging and deployment?). Or maybe we’re wasting our time and we should let AI do our dirty work for us? Who knows, but for now, I guess we keep on…